Here we introduce the idea of using heuristics models in predictive mobile game analytics. Heuristics models are simple rules-sets that we construct based on machine learning-driven analysis, but which once developed can be fielded inside a game client. Heuristics models thus address part of the problem of enabling small companies to access frugal but effective prediction models that are easy to understand, deploy and scale, but also indicates that a large component of prediction can be handled directly in the game client.
In data science there is a certain appreciation for complex models – computational requirements be damned! – and a delight in improving algorithms and models to obtain the best possible result. However, there are many situations where the goal is not necessarily the best possible solution no matter the cost, but rather a simple, neat and cheap solution where precision is weighted against cost. Business data in games, especially when drawn from games directly, are typically fairly volatile, meaning that the speed of analysis is an important factor. The sooner we can crunch the numbers and derive some useful results, the more valuable will those results be. They are also commonly highly varied, meaning that there are a lot of different features (or variables) to consider for inclusion in analysis. Combined these two factors mean we are often in need of quick solutions that at the same time help us zero in on the most useful features.
This is also the case for predictive modeling in mobile games. Trying to predict the behavior of players has in mobile games become a fairly regular occurrence, and the benefits of being able to do so are obvious. For example, if we can predict when a player is likely to stop playing, we can try to incentivize the player to not give up. At the end of things, we want to ensure the best possible user experience, and players stopping a game after a short while are not receiving that.
One problem is that many companies in the mobile gaming industry have rather small operations, and cannot afford their own in-house analytics team. Therefore there is a need to identify simple, accessible, frugal but effective prediction models to enable everyone to reap the benefits of predictive analytics. Recently we started investigating whether heuristics models could provide a solution to this problem (here is a more detailed report). A heuristic is a rule or principle, and the concept is already widely used in games in the form of design heuristics.
For example, a heuristic could be: “if more than 20 hours has elapsed since the first session of the player, that player has likely churned” – and an incentive to reengage should be activated.
Compared to machine learning algorithms, which arguably are generally more accurate in their predictions, heuristics models provide several attractive features:
1) They are easy to deploy as they can often be implemented as a simple rule systems in the client device. This is a powerful advantage which opens up the potential for automating a number of crucial tasks in mobile game analytics such as churn prediction, without the need to collect data from the client, transmit that data to a back end, crunch the numbers and then feeding the information back to the client. It essentially makes real-time decision making possible client-side.
2) They tend to have lower computational cost than machine learning-based models.
3) They are more straightforward to communicate to non-analytics decision makers and thus obtain organizational acceptance for them.
However, heuristic-based rules eschew detailed predictions at the individual level, i.e. for the individual player. This often makes them more robust for predictions in vastly different environments, but leads to a loss of granular predictive ability in stable environments.
Heuristics models can be built using various approaches. Traditionally, logic rules (heuristics) have been derived from a combination of domain expertise and statistical analysis in domains outside games, and this is often the case in practice in the games industry as well.
What we propose is adding a machine learning step in the generation of the heuristics model, which means we can take advantage of the analytical strengths of machine learning algorithms, without compromising the goal of having a simple model to work with in practice.
What we will be talking about here is using decision tree analysis to generate heuristics via the calculation of heavily pruned decision trees. Essentially this means that what we propose is using decision tree analysis, which is a machine learning model, to generate heuristics, and then applying those heuristics to predict churn (in this case – the approach can be used for any prediction task).
The heuristics have that advantage of comprising a simple set of principles that can be implemented client-side.
Here we will focus on an example F2P mobile game (iOS, 90 days, 130k players), and we will be applying a heuristics model to do rapid prediction of churn; benchmarking the model against common classification algorithms using information from three different observation windows: 1) the first session; 2) the first day of play; 3) the first week of player activity. We will skip many of the details to focus on the meat of the analysis and results, but the pre-processing and feature engineering details etc. are described here.
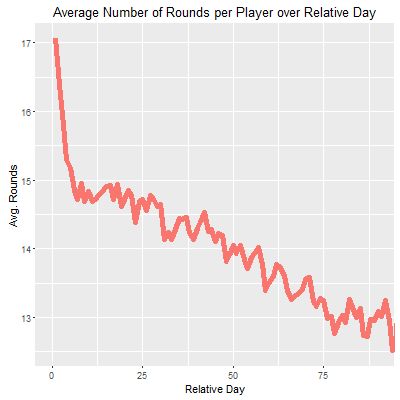
Average number of rounds played per player over relative day since date of game installation for the cohort used here.
Building heuristics models
In building a heuristic model, we used 10-fold cross validation to examine the performance of decision trees covering three different observation periods, i.e. three different lengths of time during which we capture data from the players: 1) first session only; 2) one full day; 3) the first week. The latter, an observation window of a week, is probably the most common approach (if such a thing exists) when doing churn prediction in mobile games, i.e. we capture the first weeks’ worth of data from the players, and then build prediction models to determine churn, retention etc.
Decision trees as they are applied in game analytics are explained in more detail in this book, and for games specifically in this one. Essentially, decision tree analysis uses a graphic approach to compare competing alternatives, and assign values to these alternatives, describing sequential decision problems.
For example, we might have a decision tree that specifies at a given node/branch that if players complete over 18 rounds of a game within a time period, their likelihood of churn is X%, whereas if they play less than 18 rounds, their likelihood of churn is Y%.

A simple decision tree.
The method splits the dataset into branch-like segments, and these form in inverted decision trees that originate with a root node at the top, and branch out from there. Decision trees attempt to find relationships between input values and target values in a dataset. When an input value is identified as being strongly related to a target value, all of these observations are grouped in a bin that becomes a branch in the tree. A strong relationship is formed when the value of an input variable can be used to predict the value of the target. For example, if the inter-session time is a strong predictor of retention. Decision trees allow analysts to follow the effect of different decisions or actions, and this provides insights useful for planning and testing retention strategies.
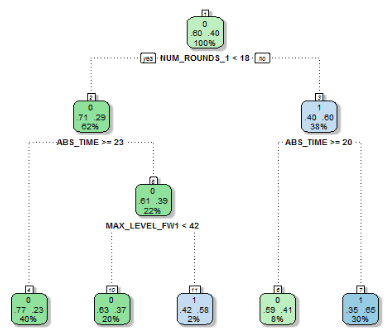
One day heuristics based on a heavily pruned Decision Tree model. The 1-day heuristics are captured by simple rules regarding number of rounds, current absence time, and maximum level reached. The splits from the corresponding tree show that absence time of more than 20 hours after installation is a reliable determinant of player churn.
For building heuristics, we use heavily pruned decision trees, i.e. trees that are cut down to their most important decision points. We limit the size of any given decision tree to keep just 3 or 4 decision rules in each heuristic set. This makes the trees less precise, but on the other hand allows for the generation of useful sets of rules which are simple enough to deploy onto a client device, and straightforward enough to communicate to non-analyst decision makers.
The details of the analysis we ran is here, but broadly, results show that one day’s worth of player information can be used to determine player behavior a week or possibly longer into the future with decent accuracy. There is a trade-off between the extent of the data collection windows (the observation period) and evaluation window – the longer the observation window, the better the prediction across the pruned decision trees and the models we benchmarked against.
To take an example, the 1-day heuristics set is captured by simple rules regarding number of rounds, current absence time, and maximum level reached. The splits from the corresponding tree intuitively show that absence time of more than 20 hours after installation is a reliable determinant of player churn. We investigate the robustness of each heuristic by examining the sensitivity of the corresponding decision tree’s accuracy with respect to different training and test data. The rules identified in this manner are straight forward to implement client-side – and can as needed be updated as the player population and the game change.
In order to evaluate the predictive strength of the heuristic set built by the pruned decision trees, we used three commonly used machine learning classifiers for each of the observation windows: Logistic Regression (LR), Support Vector Machines (SVM), and Random Forest (RF). Comparing our heuristic sets against these algorithms show that they exceed the heuristic-based decision trees, but the difference is not that big. Returning to our single-day example, the heuristic model is outperformed by only 1.2 percentage points of accuracy. For the single-session observation window, the difference was even smaller: 0.3 percentage points of accuracy. Lastly, using a full week of information the best machine learning algorithm improved accuracy over the heuristic by 0.6 percentage points. These results strongly indicate that simpler decision rules implemented client-side can be possible for short-term retention prediction in mobile games.
Feature importance
Understanding the relationships between specific predictors and retention likelihoods helps inform intervention targeting. This in itself is a topic around which we can build heuristics models based on experimentation, but here we wanted here to include a few notes on which player behaviors that most strongly relate to overall retention in each of the three feature windows (observation windows). These observations will hopefully be of use to others, even though we cannot say whether they hold true for other mobile games – please do not hesitate to add insights in the comments section or contact us directly.
Single session model: Total Rounds and Total Playtime have the strongest overall effect on retention for the single-session feature window. Additionally, Average Stars (you get stars in for levels) has a significant negative relationship with retention. We see a positive relationship for Average Duration and Average Moves, and retention rates also vary by Install Device Type: users installing the game on tablets generally exhibit lower retention relative to phone installations. Despite information from only the players first session not having much predictive power, the relationships above appear mostly intuitive: those who play longer immediately after installing the game are less likely to churn.
Single day model: Looking at the single-day window, overall playtime and consistent playtime are the main determinants of retention. Total Rounds, Total Sessions, and Average Duration are the strongest positive predictors, whereas Current Absence Time, Average Stars, and Average Time Between Sessions are the strongest negative factors.
Seven day model: For the seven day feature window Current Absence Time becomes by far the strongest predictor, dominating regression models and random forest variable importance plots. These results seem to suggest a large number of players churn very soon after installing the game, whereas those who play for longer and over a more consistent basis in the first week are much more likely to be retained in the second. These findings are largely consistent with the wider knowledge available on churn prediction in games.
Another observation is that measures related to skill (lower Average Moves, higher Average Stars) are actually inversely related to retention likelihood. This could represent certain players finding the games initial levels too easy and quickly losing interest. However, the fact that later levels are more difficult and require more moves on average may confound this relationship as players who immediately lose interest for any reason are unlikely to ever attempt these higher levels.
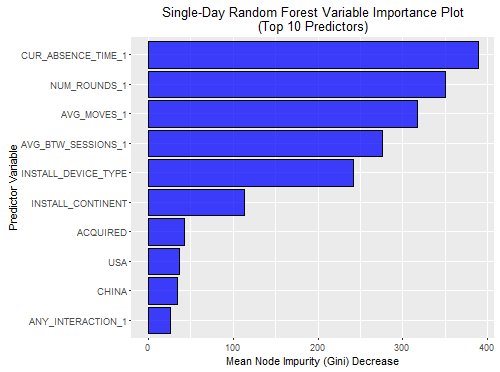
Example of feature importance results, here for the single-day random forest model. Note current absence time and number of rounds played as the most important features predicting churn.
Conclusions
The accuracies of the three classifiers exceed those of a simple heuristics set derived from a heavily pruned Decision Tree-model, but not substantially. This indicates that retaining players can be successfully determined with a short history of behavioral information and using heuristic prediction approaches.
In conclusion, heuristics modelling appears to be a strong contender for a pathway to identify simple, accessible but also relatively effective prediction models, which can be acted upon in a very direct fashion.
Our experiment, although confined to one title for now, suggest that a large part of the value of advanced prediction analytics in games can potentially be accessed by relying on static heuristic models. They are beneficial in being robust, easily understandable and simple to deploy and scale.
For a complete breakdown of the experimental work, see this report.
Please do not hesitate to add insights in the comments section or contact us directly with any questions.
Co-authored by Anders Drachen, Eric T. Lundquist, Yungjen Kung, Pranav Rao, Rafet Sifa, Julian Runge and Diego Klabjan










Great post, Anders! We went through a very similar path and found a lot of predictors in common when we try to predict churn. I am also curious about the precision and recall you got from this model. Do you mind sharing that number? Thanks!
-Tony
Hi Tony
Many thanks. The precision and accuracy rates are in the paper we link to in the post (Table 1). The work here was focused on heuristics, and thus we compromise a bit on the accuracy, F-scores etc. In the paper are references to other work on churn prediction that are focused on achieving high accuracy and precision, e.g. this one: https://andersdrachen.files.wordpress.com/2014/07/predicting_purchase_decisions_in_mobile_free_to_play_games_aiide2015.pdf
all the best
anders
Super helpful! Thanks so much, Anders!
Tony